



Tutto quello che devi sapere sul nuovo Llama 3.1

Soltanto due giorni fa (23 luglio) Meta ha presentato Llama 3.1, una versione aggiornata del suo modello di intelligenza artificiale open source. Con le sue dimensioni titaniche, la nuova versione di Llama non solo alza l'asticella delle prestazioni per i modelli accessibili pubblicamente, ma lancia anche una sfida diretta ai colossi privati dell'AI come OpenAI e Anthropic.
405 miliardi di parametri
Llama 3.1 è dotato di 405 miliardi di parametri. Si tratta di una cifra mastodontica: per contestualizzare, il precedente modello di punta di Meta, Llama 3 70B, contava "solo" 70 miliardi di parametri. Il modello è stato addestrato su oltre 15 trilioni di token, un volume di dati che eclissa qualsiasi precedente sforzo open source nel campo dell'AI generativa.
L'addestramento di un LLM di tali dimensioni non è stata impresa da poco. Meta ha dovuto spingere al limite la propria infrastruttura, impiegando oltre 16.000 GPU NVIDIA H100 - un'operazione di calcolo parallelo senza precedenti per un modello open source. Sebbene Meta non abbia divulgato il costo esatto dello sviluppo di Llama 3.1, considerando solo il prezzo delle GPU Nvidia utilizzate, si può stimare un investimento nell'ordine delle centinaia di milioni di dollari. Quanto ai dati di addestramento, l'azienda di Zuckeberg rimane vaga, facendo riferimento ad "un nuovo mix di dati online disponibili pubblicamente".
Prestazioni da capogiro
Secondo Meta, Llama 3.1 405B si pone come il primo modello open source a competere ad armi pari con i migliori modelli a scatola chiusa. Le prestazioni sono state valutate su oltre 150 dataset di benchmark, coprendo un'ampia gamma di compiti e lingue, superando spesso GPT-4o e Claude 3.5 Sonnet.
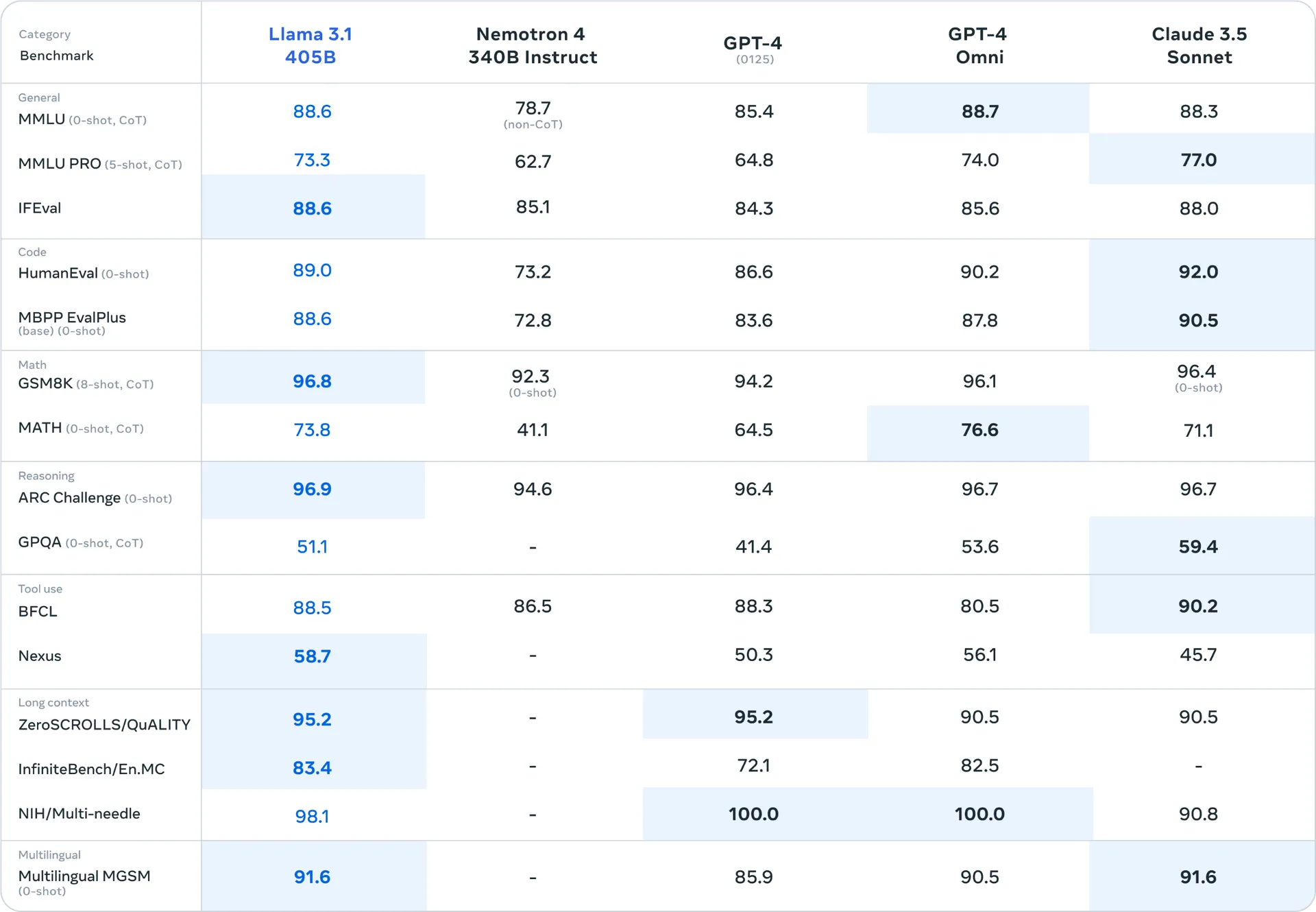 Fonte: The Verge
Fonte: The VergeMa non è solo una questione di dimensioni. L'intera famiglia Llama 3.1, che include anche le versioni ridotte da 8B e 70B parametri, presenta miglioramenti sostanziali:
- Contesto: Tutti i modelli supportano ora un contesto di 128K token, quadruplicando la capacità dei predecessori (sia Lama 3 70B che 8B hanno un contesto di 8k token). Questo permette di elaborare e comprendere testi molto più lunghi in un'unica sessione.
- Multilinguismo: La famiglia Llama 3.1 è poliglotta, supportando otto lingue con prestazioni di alto livello, tra cui francese, tedesco, hindi, italiano e spagnolo.
- Uso avanzato degli strumenti: I modelli eccellono nell'interfacciarsi con strumenti esterni, aprendo la strada a applicazioni più complesse e integrate.
- Ragionamento: Le capacità di ragionamento sono state significativamente migliorate, permettendo analisi più profonde e risoluzioni di problemi più complessi.
L'architettura di Llama 3.1
Nonostante le dimensioni imponenti, Meta ha optato per un'architettura relativamente semplice. Llama 3.1 405B utilizza un transformer decoder-only standard, evitando approcci più complessi come i mixture-of-experts. Questa scelta mira a massimizzare la stabilità dell'addestramento e la scalabilità del modello.
Il processo di sviluppo ha incluso un'iterativa procedura post-training, con alternanza di fine-tuning supervisionato e ottimizzazione diretta delle preferenze; alcuni miglioramenti significativi nella qualità e quantità dei dati di pre-training e post-training e il ricorso a tecniche avanzate di quantizzazione, passando da 16-bit (BF16) a 8-bit (FP8) per rendere possibile l'inferenza su singoli nodi server.
L'ecosistema Llama: più di un semplice modello
Meta non si è limitata a rilasciare un modello: Llama 3.1 è concepito come parte di un ecosistema più ampio, che include Llama Guard 3 (un modello di sicurezza multilingue per un uso responsabile dell'AI); Prompt Guard (un filtro contro i prompt malevoli) e Llama Stack (una proposta di API standardizzata per facilitare l'interoperabilità tra diversi progetti basati su Llama).
Inoltre, Meta ha collaborato con oltre 25 partner, tra cui AWS, NVIDIA, Google Cloud, Microsoft Azure, e Databricks, per offrire servizi basati su Llama 3.1 fin dal primo giorno. Questo garantisce un'ampia gamma di opzioni per gli sviluppatori che desiderano implementare Llama 3.1 nei loro progetti.
L'impatto sull'open source
Per la prima volta, un modello pubblicamente accessibile si pone come alternativa credibile ai giganti closed-source: si tratta di un passo avanti verso la democratizzazione dell'AI, corroborato dalla recente presentazione di GPT 4-o mini e Mistral NeMo (a tal proposito, consulta questo articolo)
Mark Zuckerberg, in una lettera aperta, ha sottolineato l'importanza dell'approccio open source:
"L'open source garantirà che più persone in tutto il mondo abbiano accesso ai benefici e alle opportunità dell'AI, che il potere non sia concentrato nelle mani di pochi, e che la tecnologia possa essere distribuita in modo più uniforme e sicuro nella società."
Anche Yann LeCun - importante ricercatore e AI Scientist per Meta (lo abbiamo presentato qui) - ha evidenziato su LinkedIn i benefici dell'open source, sia per gli sviluppatori che per Meta che per il "mondo".
Meta AI: l'assistente basato su Llama 3.1
Meta ha Llama 3.1 nel suo assistente A (Meta AI), rendendolo disponibile su WhatsApp, Instagram e Facebook. L'azienda prevede che Meta AI supererà l'utilizzo di ChatGPT entro la fine del 2024. Tuttavia, per motivi di costi, l'accesso al modello da 405 miliardi di parametri è limitato e il chatbot non è ancora disponibile in Europa.
Conclusioni
Llama 3.1 405B non è solo un altro modello linguistico. È una dichiarazione d'intenti da parte di Meta, un tentativo di ridefinire le regole del gioco nell'AI generativa. Se l'approccio open source di Meta avrà successo, potremmo assistere a una vera e propria democratizzazione dell'AI, con implicazioni non trascurabili per industrie, ricerca e società.
