



Reflection 70B: prima di parlare, pensa!

Uno dei grandi problemi degli LLM attuali è l'incapacità di riflettere sugli output che loro stessi hanno generato. Ne conseguono disinformazione e allucinazioni varie (a volte, bisogna ammetterlo, molto divertenti, come quella volta in cui Google consigliò di mangiare almeno una roccia al giorno).
Proprio per risolvere questo problema è stato annunciato - soltanto pochi giorni fa - un nuovo modello open-source capace di "riflettere" prima di dire qualsiasi cosa. Reflection 70B - questo il nome - sarebbe infatti in grado di controllare ciascuna delle sue risposte ed è programmato per non dare una risposta finché non è in grado di dimostrare perché è corretta. Ma, forse, non è tutto oro quel che luccica.
L'annuncio di Shumer
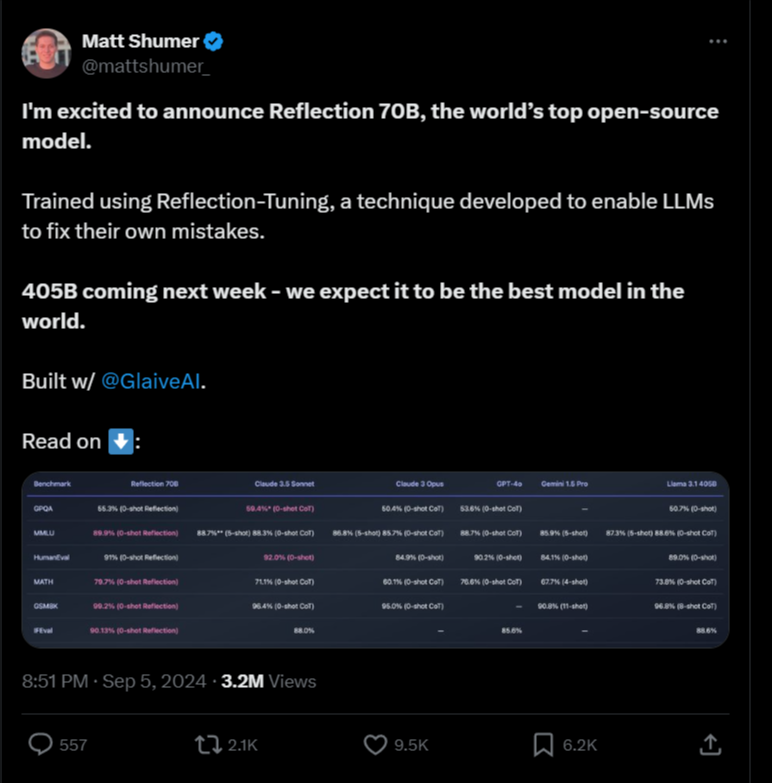
Il 5 settembre 2024, Matt Shumer, CEO di HyperWrite (precedentemente nota come OthersideAI), ha presentato Reflection 70B su X, trionfalmente descrivendolo come "il miglior modello open-source al mondo". Basato sull'architettura open-source Llama 3.1 70B Instruct di Meta, questo nuovo modello si distinguerebbe rispetto ai chatbot concorrenti grazie a una tecnologia innovativa chiamata "Reflection-Tuning".
Cos'è il Reflection-Tuning?
Il Reflection-Tuning è una tecnica che insegna ai modelli linguistici di grandi dimensioni a rilevare gli errori nel proprio ragionamento e a correggersi. In pratica, Reflection 70B aggiunge fasi distinte di ragionamento e utilizzando token speciali. Quando genera risposte, il modello esplicita il suo processo di pensiero all'interno di tag speciali <thinking>, rivede potenziali errori con tag <reflection>, e infine presenta una risposta raffinata all'interno di tag <output>. Questo permette al modello di individuare gli errori prima di fornire una risposta finale all'utente, riducendo le "allucinazioni" e aumentando l'affidabilità.
Prestazioni impressionanti (almeno sulla carta)
Secondo i benchmark iniziali pubblicati da HyperWrite, Reflection 70B ha mostrato miglioramenti significativi nella mitigazione delle allucinazioni rispetto ad altri modelli ben più famosi. Ecco alcuni dei risultati più impressionanti:
- MMLU (Massive Multitask Language Understanding): 89,9%
- MATH: 79,7%
- IFEval: 90,1%
Questi punteggi sembravano superare quelli di modelli ben noti come GPT-4 di OpenAI e Claude 3.5 Sonnet di Anthropic, confermando l'efficacia di Reflection 70B nel generare risposte accurate e contestualmente rilevanti. Un'AI del genere sarebbe indubbiamente utile nella ricerca scientifica (potrebbe aiutare nella stesura di articoli di ricerca con un minor rischio di introdurre errori o interpretare male i dati), nell'analisi legale (dove la precisione è fondamentale) e nel coding e debugging (grazie alla capacità del modello di individuare e correggere errori logici).
La controversia: quando l'hype incontra la realtà
Tuttavia, l'entusiasmo iniziale per Reflection 70B è stato rapidamente offuscato da dubbi e controversie. Soltanto un giorno dopo l'annuncio, il 7 settembre, l'organizzazione Artificial Analysis ha pubblicato la propria analisi su X, affermando che la loro valutazione del punteggio MMLU di Reflection 70B risultava identica a quella di Llama 3 70B e significativamente inferiore a quella di Llama 3.1 70B di Meta.

In risposta, Shumer ha dichiarato che i pesi di Reflection 70B sono stati "incasinati durante il processo di upload" su Hugging Face, e che questo problema avrebbe causato prestazioni inferiori rispetto alla versione "API interna" di HyperWrite. L'8 settembre, Artificial Analysis ha posto due domande che mettono in dubbio le affermazioni iniziali di Shumer:
- Perché è stata pubblicata una versione che non è quella testata tramite l'API privata di Reflection?
- Perché i pesi del modello della versione testata non sono stati ancora rilasciati?
Nel frattempo, gli utenti di varie community di machine learning e AI su Reddit hanno messo in discussione le prestazioni dichiarate e le origini di Reflection 70B. Alcuni hanno fatto notare che, in base a un confronto tra modelli pubblicato su Github da una terza parte, Reflection 70B sembra essere una variante di Llama 3 piuttosto che di Llama 3.1.
Accuse di frode
La situazione è precipitata il 9 settembre, quando un utente di X, Shin Megami Boson, ha apertamente accusato Shumer di "frode nella comunità di ricerca sull'AI", pubblicando una lunga lista di screenshot sulla inesattezza di quanto dichiarato originariamente. Altri hanno accusato il modello di essere in realtà un "wrapper" o un'applicazione costruita sopra il rivale closed-source Claude 3 di Anthropic.
Tuttavia, non tutti sono convinti di queste accuse. Alcuni utenti di X hanno difeso Shumer e Reflection 70B, e alcuni hanno pubblicato post sulle prestazioni del modello da loro riscontrate.
Cosa ci aspetta?
Al momento, la comunità AI attende con il fiato sospeso la risposta di Shumer e l'aggiornamento dei pesi del modello su Hugging Face. La rapida ascesa e l'altrettanto rapido declino di Reflection 70B dimostrano quanto velocemente il ciclo dell'hype nell'AI possa precipitare.
Questa vicenda solleva importanti questioni sulla trasparenza e la verificabilità nel campo dell'IA open-source. Mentre attendiamo ulteriori sviluppi, è chiaro che la strada verso un'IA più affidabile e trasparente è ancora lunga e piena di sfide.
