



il nuovo Google Gemini-Exp-1114 supera Chat GPT e Claude

Il 14 novembre Google ha rilasciato Gemini-Exp-1114, un nuovo modello sperimentale che ha già spodestato Chat GPT aggiudicandosi il primo nella classifica di LMSYS Org, una piattaforma di riferimento per valutare le prestazioni dei modelli linguistici avanzati.
LMArena: la piattaforma di valutazione degli LLM
LMArena (di cui abbiamo parlato in questo articolo), conosciuta anche come Chatbot Arena, è un'importante piattaforma open-source sviluppata dai team di LMSYS e UC Berkeley SkyLab. Permette una valutazione comunitaria e interattiva dei modelli attraverso confronti diretti tra loro, favorendo test più realistici e affidabili delle prestazioni dei LLM.
Come leggere la classifica? Un confronto
LMArena adotta diversi parametri per valutare i modelli:
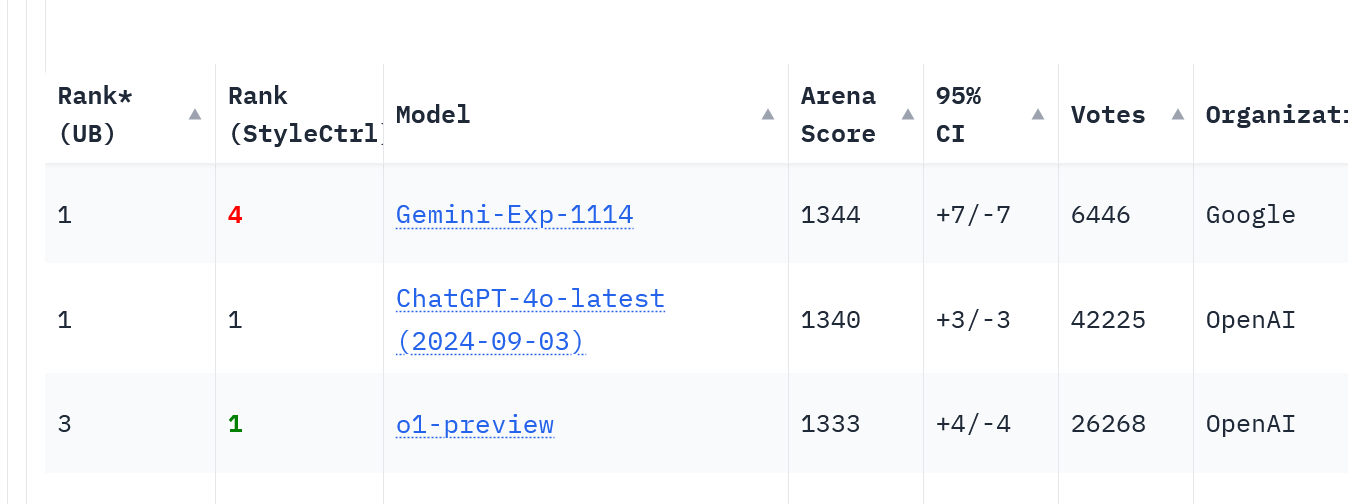
Classifica (UB): misura le prestazioni complessive senza tenere conto di controlli stilistici.
Classifica (StyleCtrl): valuta la capacità del modello di adattare risposte in base a toni e stili specifici richiesti.
Gemini-Exp-1114 si posiziona al 1° posto per UB e al 4° per StyleCtrl contro il 1° posto di ChatGPT-4.0, mostrando che quest’ultimo è ancora il migliore nel controllo dello stile. Ma, ricordiamo, si tratta ancora di un modello sperimentale.
Punteggio Arena
Gemini-Exp-1114 ha ottenuto un punteggio leggermente più alto (1344) rispetto a ChatGPT-4.0 (1340), suggerendo un vantaggio nelle prestazioni medie su compiti complessi.
Intervallo di Confidenza (IC) al 95%
Nella classifica, l'intervallo di confidenza (IC) è una misura che indica l'affidabilità del punteggio di un modello. Un intervallo di confidenza più piccolo suggerisce prestazioni più coerenti. Gemini ha un IC di ±7, mentre ChatGPT-4.0 ha ±3, dunque il modello di OpenAI è più stabile nonostante il punteggio leggermente inferiore di media. In breve, questo significa che c'è una probabilità del 95% che il punteggio effettivo di Gemini si trovi entro 7 punti dal suo punteggio medio, mentre il punteggio effettivo di ChatGPT si trova entro 3 punti dal suo punteggio medio.
Numero di voti
ChatGPT-4.0 vanta 42.225 voti, contro i 6.446 di Gemini-Exp-1114, punteggio dovuto al recente rilascio del modello di Google.
Modelli sperimentali Gemini
I modelli sperimentali, come suggerisce il nome, sono versioni avanzate utilizzate per raccogliere feedback e testare nuove funzionalità. Google avverte che tali modelli possono essere ritirati o modificati senza preavviso e ne sconsiglia l’utilizzo in contesti produttivi. In ogni caso, potete provare il nuovo Gemini su Google AI Studio.
Conclusioni
Gemini-Exp-1114 segna un passo avanti significativo nella competizione tra i principali LLM. Tuttavia, essendo ancora un modello sperimentale, è presto per trarre conclusioni definitive. Rimane interessante vedere come questa competizione possa alzare ulteriormente gli standard, offrendo modelli sempre più performanti e innovativi.
Fonte: Medium
