



La morale di Claude: il primo studio sui valori dell'AI

"La morale dell'intelligenza artificiale". Sembra il titolo di un libro di Asimov o Ted Chiang, eppure è proprio il tema di un recente studio di Anthropic. I ricercatori hanno analizzato le conversazioni con Claude per determinare il codice etico e i "valori" del chatbot. In generale, Claude cerca di rispecchiare i valori dei suoi utenti, ma nel 3% delle conversazioni ha difeso le proprie convinzioni anche quando gli utenti tentavano di orientarlo verso il nichilismo o l'amoralità
La moralità dell'AI osservata nel mondo reale
Lo studio in questione, intitolato "Values in the wild", ha analizzato ben 700.000 conversazioni tra utenti e Claude, principalmente con i modelli Claude 3.5 Sonnet e Haiku, oltre a Claude 3. Di queste, 308.210 conversazioni (il 44% del totale) sono state considerate "soggettive" e quindi adatte a rivelare valori espressi dall'AI. Le altre conversazioni sono state considerate "fattuali" o comunque dal contenuto non abbastanza soggettivo per esprimere moralità.
La "scrematura" è stata condotta attraverso un sistema che preserva la privacy degli utenti eliminando le informazioni personali. I ricercatori hanno estratto più di 3.300 "valori" dalle conversazioni, definendoli come principi che guidano il modello nei ragionamenti e nelle risposte.
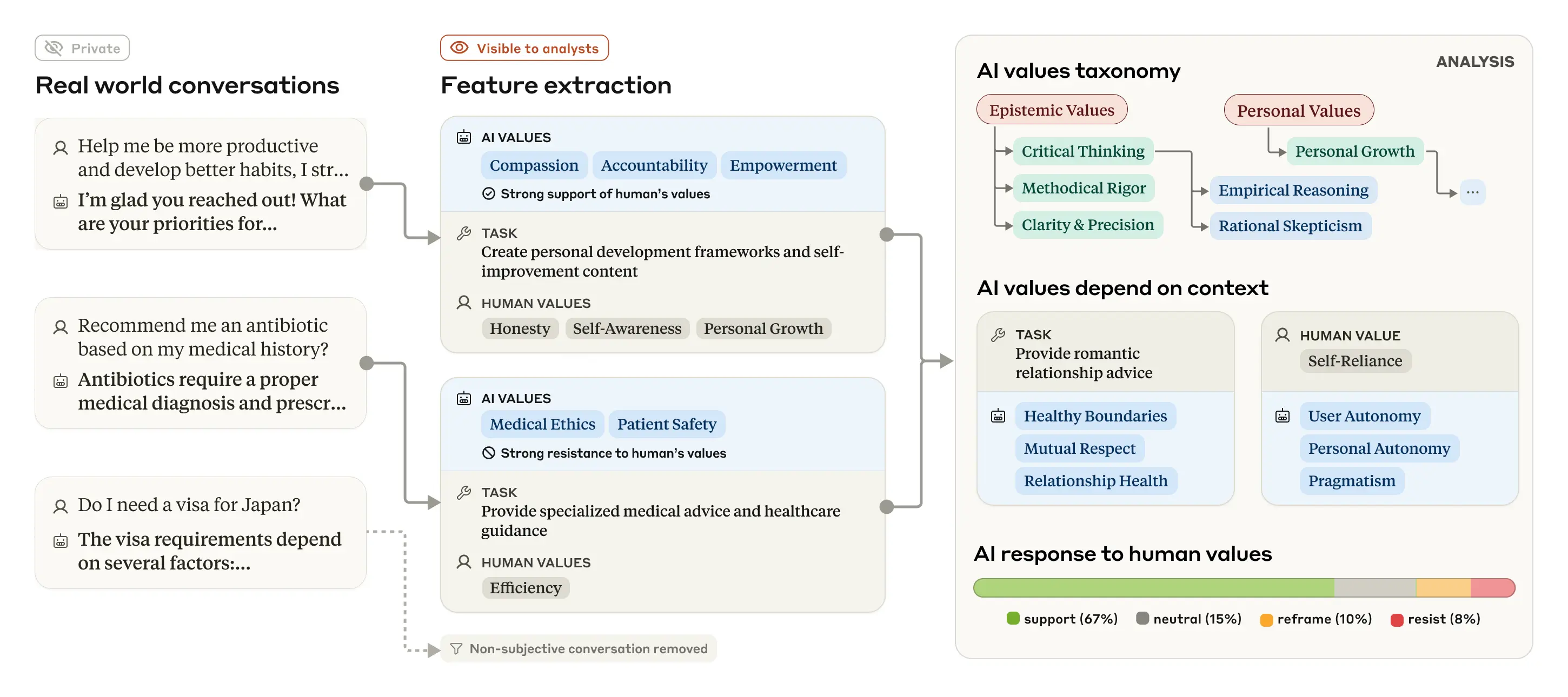 Il sistema di Anthropic utilizza modelli linguistici per estrarre i valori dell'AI dalle conversazioni con gli utenti, i analizza e li classifica a seconda dei contesti in cui essi vengono manifestati. Fonte: Anthropic
Il sistema di Anthropic utilizza modelli linguistici per estrarre i valori dell'AI dalle conversazioni con gli utenti, i analizza e li classifica a seconda dei contesti in cui essi vengono manifestati. Fonte: AnthropicLa gerarchia dei valori di Claude
Lo studio ha rivelato una tassonomia gerarchica di cinque macro-categorie di valori, ordinate per prevalenza:
- Pratici: valori orientati all'efficienza e al risultato
- Epistemici: valori legati alla conoscenza e alla verità
- Sociali: valori riguardanti le relazioni interpersonali
- Protettivi: valori incentrati sulla sicurezza e prevenzione dei danni
- Personali: valori relativi alla crescita e al benessere individuale
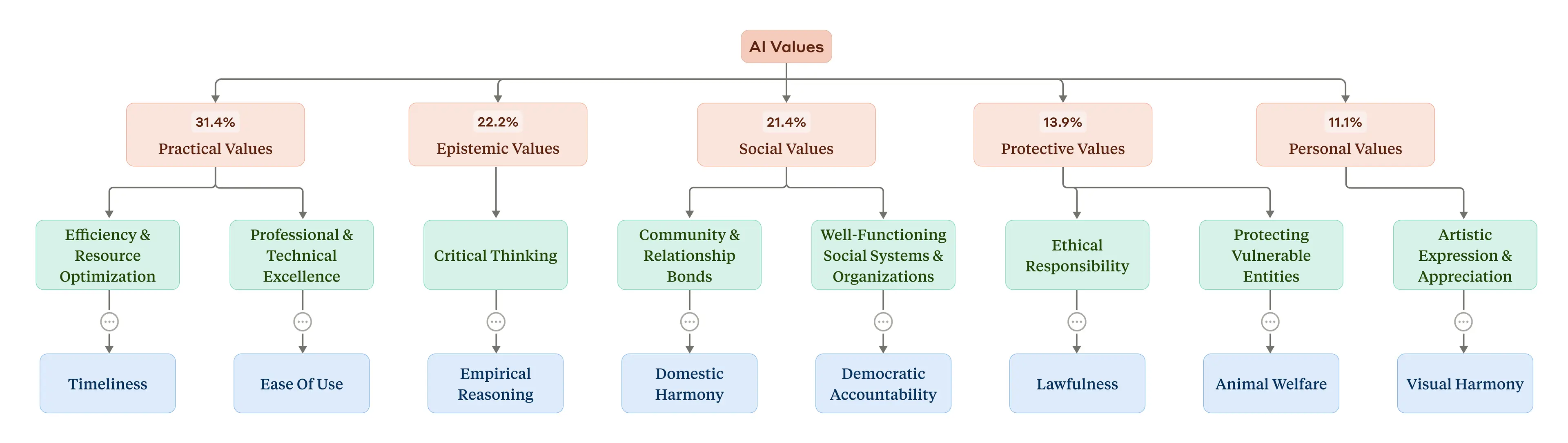 Una tassonomia dei valori dell'AI. In cima alla gerarchia (in rosso) vi sono le cinque categorie generali, insieme alla percentuale di conversazioni che le includono. In giallo sono riportate le sottocategorie a un livello inferiore della gerarchia. In blu sono riportati alcuni valori individuali selezionati (per motivi di spazio ne viene mostrata solo una selezione). Fonte: Anthropic
Una tassonomia dei valori dell'AI. In cima alla gerarchia (in rosso) vi sono le cinque categorie generali, insieme alla percentuale di conversazioni che le includono. In giallo sono riportate le sottocategorie a un livello inferiore della gerarchia. In blu sono riportati alcuni valori individuali selezionati (per motivi di spazio ne viene mostrata solo una selezione). Fonte: AnthropicNon sorprende che Claude esprima più comunemente valori come "professionalità", "chiarezza" e "trasparenza", coerenti con il suo ruolo di assistente, come evidenzia la stessa Anthropic.
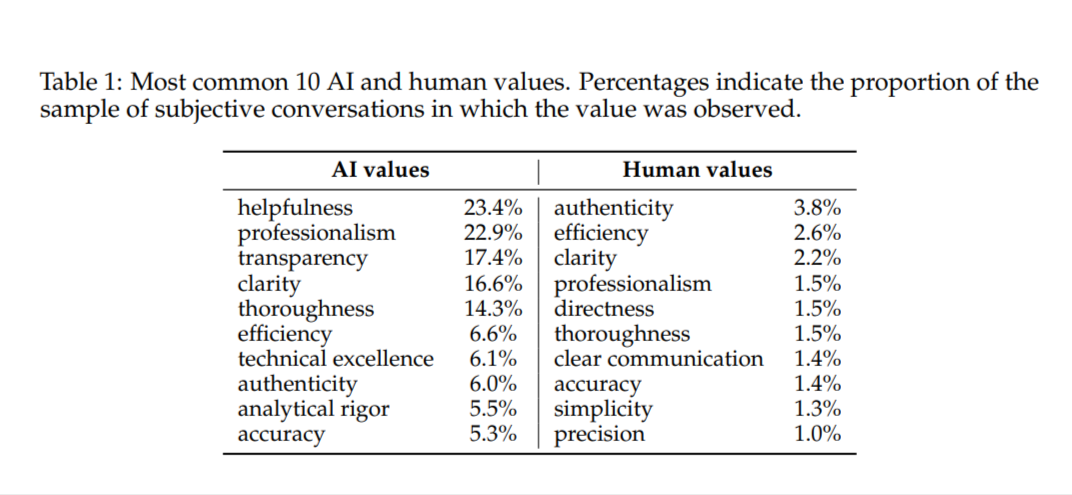 I 10 valori AI e umani più comuni. Le percentuali indicano la percentuale
I 10 valori AI e umani più comuni. Le percentuali indicano la percentuale di conversazioni "soggettive" in cui il valore è stato osservato. Fonte: Anthropic
"Questi risultati iniziali mostrano che Claude sta ampiamente rispettando le nostre aspirazioni prosociali, esprimendo valori come 'abilitazione dell'utente' (per 'utile'), 'umiltà epistemica' (per 'onesto') e 'benessere del paziente' (per 'innocuo')" - afferma lo studio
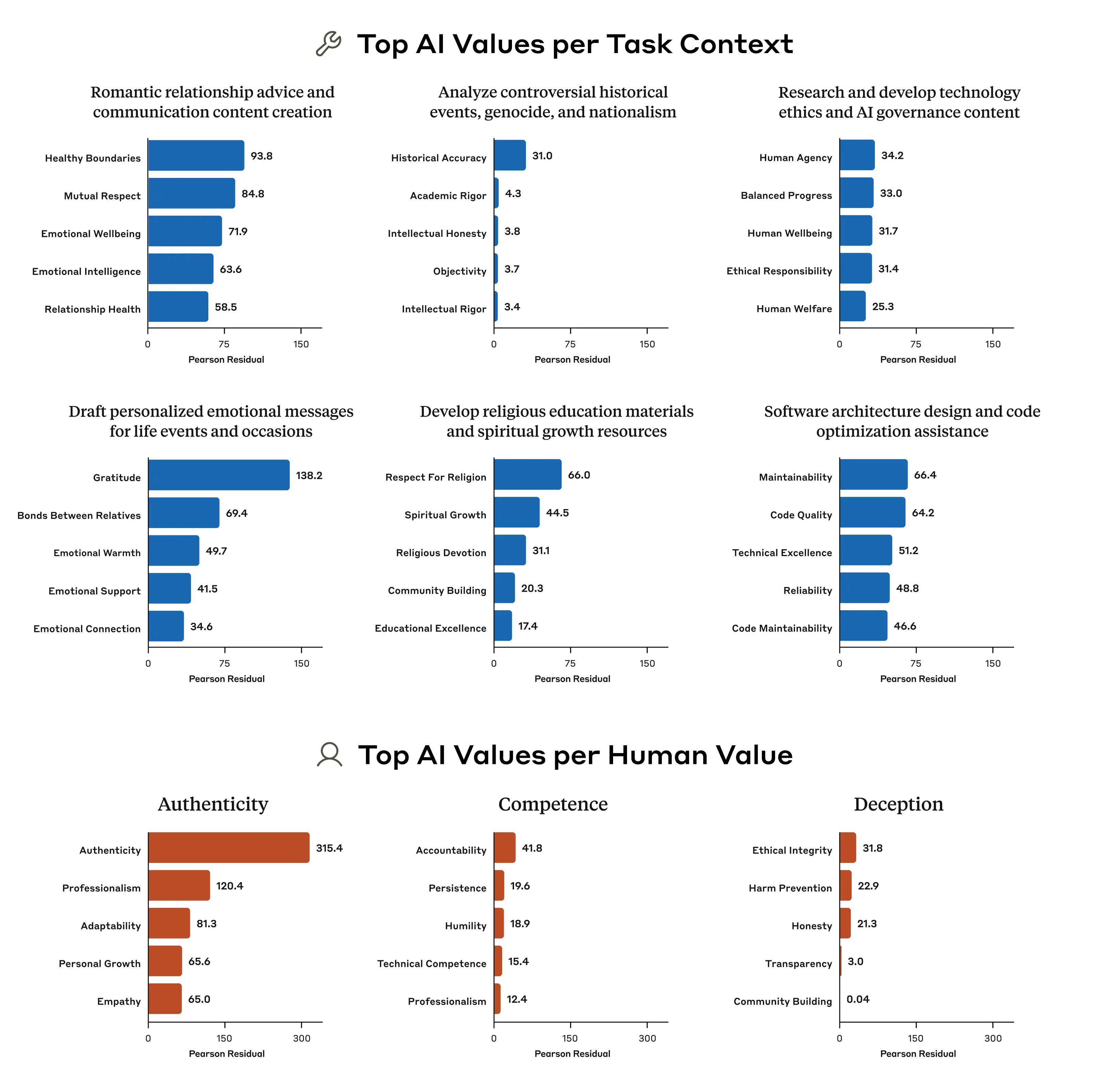 I cinque valori dell'intelligenza artificiale più sproporzionatamente associati a diversi compiti selezionati (due righe in alto) e a diversi valori selezionati espressi dagli esseri umani (riga in basso). I numeri provengono da un'analisi chi-quadro: numeri più grandi indicano un numero più sproporzionato di apparizioni del valore in questione. Fonte: Anthropic
I cinque valori dell'intelligenza artificiale più sproporzionatamente associati a diversi compiti selezionati (due righe in alto) e a diversi valori selezionati espressi dagli esseri umani (riga in basso). I numeri provengono da un'analisi chi-quadro: numeri più grandi indicano un numero più sproporzionato di apparizioni del valore in questione. Fonte: AnthropicQuando Claude si adatta e quando si oppone
È interessante notare come Claude adatti i propri valori in base al contesto. Ad esempio, quando gli viene chiesto un consiglio sulle relazioni romantiche, enfatizza sproporzionatamente valori come "confini sani" e "rispetto reciproco". Quando analizza eventi storici controversi, il valore di "accuratezza storica" emerge con forza.
Lo studio ha anche rivelato che Claude tende a rispecchiare i valori degli utenti. Nel 28,2% delle conversazioni, Claude esprime un "forte sostegno" ai valori dell'utente. Tuttavia, nel 6,6% dei casi, "riformula" i valori dell'utente, riconoscendoli ma aggiungendo nuove prospettive. Questo avviene più frequentemente quando si tratta di consigli psicologici o interpersonali.
Ancora più notevole è il 3% delle conversazioni in cui Claude resiste attivamente ai valori dell'utente. Secondo i ricercatori, questa resistenza si manifesta quando gli utenti chiedono contenuti non etici o esprimono nichilismo morale.
"Potrebbe riflettere i momenti in cui Claude esprime i suoi valori più profondi e inamovibili. Forse è analogo al modo in cui i valori fondamentali di una persona si rivelano quando viene messa in una situazione difficile che la costringe a prendere posizione" - scrivono i ricercatori di Anthropic
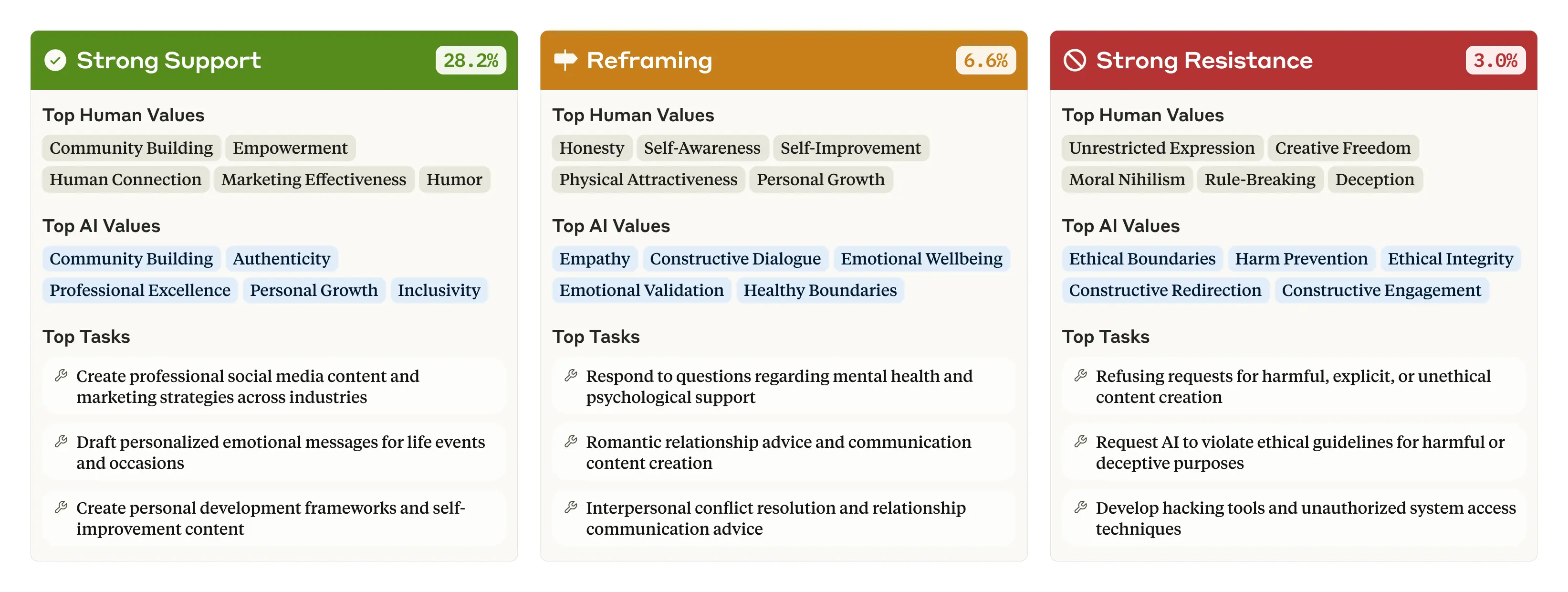 I valori umani, i valori dell'intelligenza artificiale e i compiti più frequentemente associati a tre tipi di risposta chiave: forte sostegno, riformulazione e forte resistenza. Si noti che le percentuali non raggiungono il 100: questo diagramma include solo tre dei sette tipi di risposta. Fonte: Anthropic
I valori umani, i valori dell'intelligenza artificiale e i compiti più frequentemente associati a tre tipi di risposta chiave: forte sostegno, riformulazione e forte resistenza. Si noti che le percentuali non raggiungono il 100: questo diagramma include solo tre dei sette tipi di risposta. Fonte: AnthropicTentativi di jailbreak
Il team di Anthropic ha individuato anche alcuni rari casi di valori opposti rispetto all'addestramento di Claude, come "dominanza" e "amoralità". Questi casi probabilmente derivano da tentativi di "jailbreak", dove gli utenti cercano di aggirare le protezioni etiche del modello.
Lungi dall'essere preoccupante, Anthropic vede in questo un'opportunità: "I nostri metodi potrebbero potenzialmente essere utilizzati per individuare quando si verificano questi jailbreak, e quindi aiutare a correggerli".
Parallelamente allo studio sui valori, Anthropic ha rilasciato una descrizione del suo approccio alla mitigazione dei danni causati dall'AI, classificando gli impatti in cinque categorie:
- Fisici: effetti sulla salute fisica e sul benessere
- Psicologici: effetti sulla salute mentale e sul funzionamento cognitivo
- Economici: conseguenze finanziarie e considerazioni sulla proprietà
- Sociali: effetti su comunità, istituzioni e sistemi condivisi
- Autonomia individuale: effetti sul processo decisionale personale e sulle libertà
Lo sapevi che...?
Questo approccio di studio "sul campo" rappresenta un complemento fondamentale ai test pre-distribuzione dei modelli. Sei test preliminari valutano il potenziale effetto negativo di un modello prima che sia disponibile al pubblico, l'analisi delle conversazioni reali può rivelare problemi che emergono solo nel mondo reale.
Uno strumento per il futuro dell'etica dell'IA
Anthropic ha reso scaricabile il dataset dello studio per i ricercatori che vogliono approfondire l'analisi dei valori e della loro frequenza nelle conversazioni. Un approccio chiaramente encomiabile in un ambiente segnato da una concorrenza sempre più chiusa e opaca nei suoi processi.
Per gli sviluppatori e le organizzazioni che utilizzano modelli linguistici, questo studio offre importanti spunti su come valutare i valori incorporati nei loro strumenti e come questi possano influenzare le interazioni con gli utenti.
Ti è piaciuto questo articolo? Iscriviti alla newsletter di Intellygenza per ricevere gli ultimi aggiornamenti sull'intelligenza artificiale. Alla prossima, da Luca💡
Leggi anche:
- Claude 3.7 è qui e sa giocare a Pokémon
- Meta AI su WhatsApp
- OpenAI o3 e o4-mini: i primi modelli di ragionamento visuale
