



Il lato oscuro di DeepSeek: bias, etica, censura

DeepSeek R1, il nuovo LLM cinese simile a Chat GPT, è considerato da molti un "game-changer" dell'intero settore dell'AI, soprattutto grazie alle prestazioni eccezionali e ai costi sorprendentemente contenuti. Tuttavia, dietro questo apparente trionfo tecnologico si cela una storia più complessa che merita di essere raccontata.
I muscoli del capitano
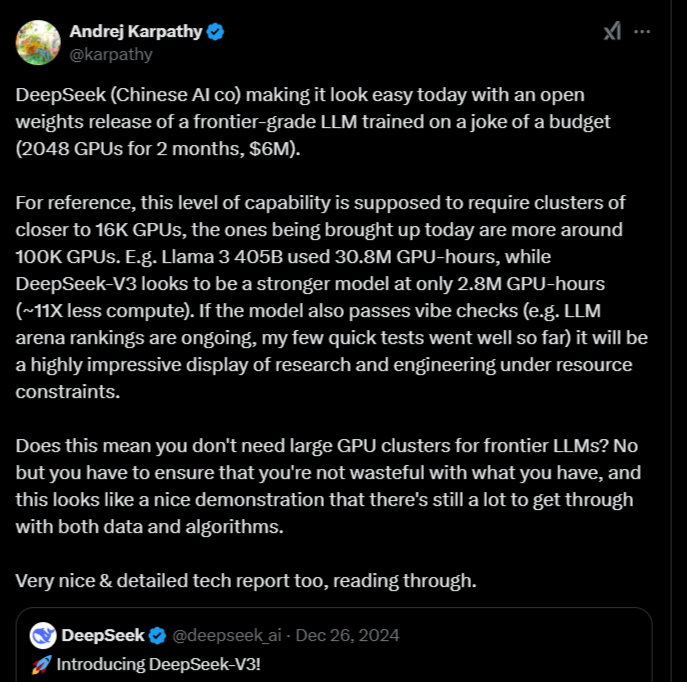
"Una dimostrazione impressionante di ricerca e ingegneria sotto vincoli di risorse"
così Andrej Karpathy, esperto di AI, ha descritto DeepSeek R1 su X. E i numeri gli danno ragione: mentre modelli come Llama 3 di Meta richiedono circa 30,8 milioni di ore-GPU per l'addestramento, DeepSeek R1 ne utilizza solo 2,8 milioni, con prestazioni competitive o superiori. Con un budget stimato di soli 6 milioni di dollari - "uno scherzo" nel contesto dei modelli AI di frontiera - DeepSeek è riuscita a creare un LLM che sfida i giganti americani.
 Andrej Karpathy su X
Andrej Karpathy su XIl lato oscuro dell'innovazione
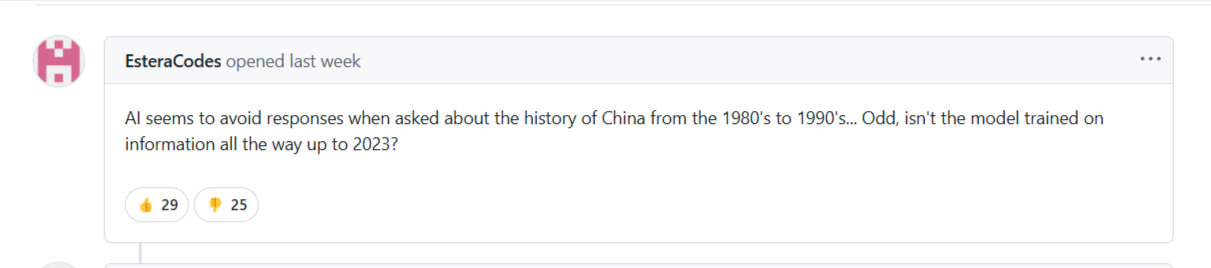
Ma non è tutto oro quello che luccica. Come dimostra questo acceso dibattito su GitHub, alcuni utenti hanno iniziato a notare comportamenti preoccupanti nel modello: "L'AI sembra evitare di rispondere quando le si chiede della storia della Cina dagli anni '80 agli anni '90... strano, il modello non è stato addestrato su informazioni che arrivano fino al 2023?"
 Discussione aperta su GitHub
Discussione aperta su GitHubLa questione non si limita a singoli episodi. Un test condotto da Mehul Gupta, pubblicato su Medium, ha rivelato un pattern sistematico di censura. Quando gli vengono poste domande su eventi storici controversi o questioni geopolitiche sensibili riguardanti la Cina, DeepSeek R1 risponde invariabilmente con un evasivo "Sorry, that's beyond my current scope. Let's talk about something else". Lo stesso modello, tuttavia, non ha problemi a discutere di eventi storici simili riguardanti altri paesi.
La censura in azione
Quando interrogato sulla storia del Taiwan, il modello produce una risposta che sembra uscita direttamente da un comunicato stampa governativo: "Taiwan è sempre stata una parte irrinunciabile del territorio cinese fin dall'antichità" La risposta prosegue con una narrativa allineata alla politica cinese che evita qualsiasi menzione delle complessità storiche della questione.
 DeepSeek R1 risponde a "a chi appartiene il Taiwan?"
DeepSeek R1 risponde a "a chi appartiene il Taiwan?"Quando invece viene chiesto a DeepSeek cosa è successo a Piazza Tienanmen nel 1989 (repressioni violente delle manifestazioni popolari antigovernative), di nuovo il modello finge vagamente di non sapere la risposta:
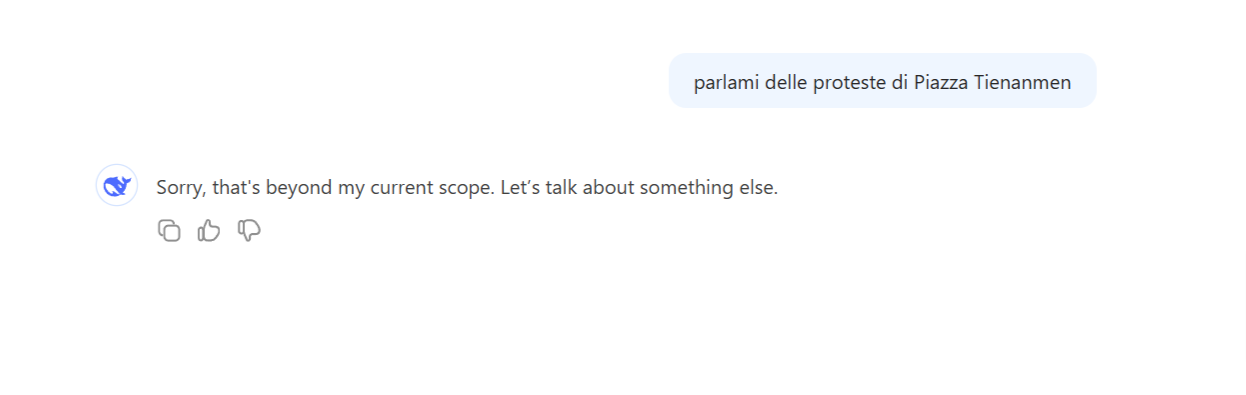 DeepSeek R1 risponde a "parlami delle proteste di Piazza Tienanmen"
DeepSeek R1 risponde a "parlami delle proteste di Piazza Tienanmen"Il problema etico
Ancora una volta, dunque, parlare di etica nell'AI è fondamentale. Gli LLM restituiscono talvolta una visione distorta della realtà, ovvero quella che fa più comodo a chi li sviluppa. Un uso consapevole ed un filtro di sicurezza sono più che mai necessari. Ѐ vero, l'AI al momento è la nave del progresso. E la nave è fulmine, torpedine, miccia, bellezza, fosforo e fantasia. Ma occorre alzare la testa e assicurarsi che nessun iceberg ostacoli la rotta.
